


Who Let The Dogs Out?
The critical role of AI training data


It’s a well-known strategy for tech-oriented startup companies to take their existing business plan, sprinkle in the words “AI” or “machine learning” at key points within it, and magically expect to become an investor darling.
It’s a bit like listening to what’s widely considered one of the worst songs in human history, with an accompanying video they clearly spent all of five minutes making:
…and expecting it to instantly become one of the greatest songs ever…
…just by adding “artificial intelligence” or “machine learning” (or both).

While AI, machine learning, and a newer term, “deep learning,” often can cause backlash from potential investors listening to a pitch in a boardroom, the fact is that these concepts have changed the world.
Computing used to involve combining known rules, and known data, to produce answers.
AI has flipped that script, allowing technology to combine known answers, and known data, to produce the original set of rules.
This slide, taken from a fantastic talk given by Google’s Laurence Moroney at their I/O 2019 conference, illustrates this:
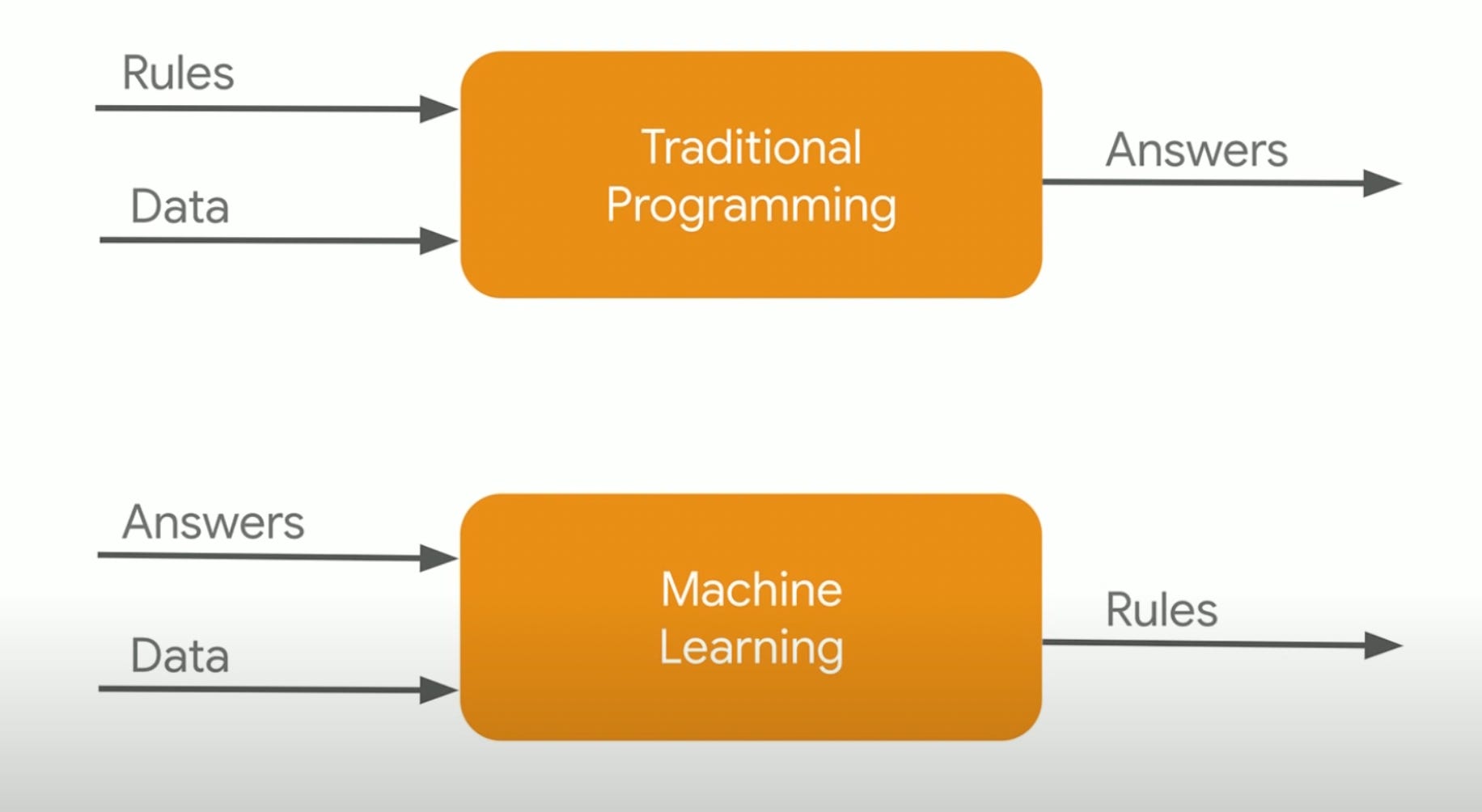
Quick! Which ingredient is needed in both scenarios above?
That would be data!

Dr. Daniela Braga worked for seven years at Microsoft, as part of a high-velocity and award-winning two-decade career working with speech, voice, and data.
Five years ago, she co-founded DefinedCrowd, where she is now CEO.
We’ve gotten to know her and her team well through multiple conferences of ours. You may have noticed their banner within this daily letter - they are the current sponsor of This Week In Voice VIP.
I’d like to think I’d tell you they’re a phenomenal group of folks, even if that weren’t the case, because they are.

There are three types of data which powers AI and machine learning today:
Training data - this is most of it. This is the voluminous data needed to educate machine learning models to help them make predictions of future outcomes. This data teaches machine learning models how to ride a (metaphorical) bike.
Validation data - this comes next, and is a small, new subset of data used to test that your machine learning model actually learned something from all the training data it just ingested and processed. This data helps unearth whether the machine learning model now knows how to ride that bike, albeit with training wheels on.
Testing data - this is the final step, in which data is provided to the machine learning model absent the annotation used during the initial processes. This is now the test to see if the machine learning model can ride the bike…with no training wheels.
Collectively, it takes a massive amount of data to even attempt to do anything within the AI and machine learning sandbox.
This is precisely where DefinedCrowd’s new service, DefinedData, steps in, to allow individuals and companies to purchase off-the-shelf data sets.
Machine learning teams building AI models have always faced one particularly pressing problem, and that is continuous access to highly accurate data. When technology focused companies want to launch their AI initiatives into the market quickly, they simply don’t have the time to collect and validate the data required to do so.
Companies with their own accumulated data will be able to use DefinedData’s marketplace to turn that data into a revenue stream, licensing it to third-parties.
The types of data available within the marketplace will also expand over time.

If AI and machine learning done right is the equivalent of Johnny B. Goode, then partnering with DefinedCrowd is quite obviously this fantastic duet:
And as I’ve closed every letter almost since we started doing this weeks ago: if you like what we’re doing with This Week In Voice VIP, and am enjoying this daily cocktail of voice, AI, and storytelling, don’t bother thanking me.
Go thank DefinedCrowd.
I’ll be back tomorrow with a letter about Project Voice, discussing a major announcement we’ll make tomorrow about the #1 event for voice tech and AI in America.
